Table of Contents
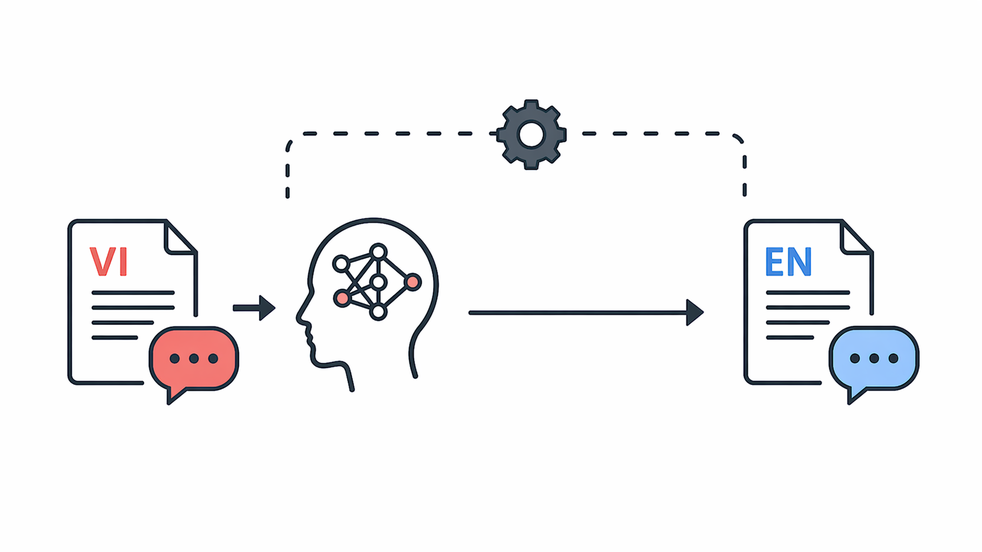
Vietnamese to English
This module converts Vietnamese text and content snippets into clear English, supporting platform growth as a scalable web system by making multilingual records easier to review, reuse, and manage.
Written date: 10/18/2025 11:36:36Digital Suite
Introduction
This VI-to-EN translation module is a high-performance microservice in the HUST Media ecosystem. Built for scalable platforms, it translates Vietnamese text and HTML content into English. As a core pipeline component, it automates content localization for production environments.
Practical Notes
Implementation leverages advanced translation models via a dedicated Flask AI server. It utilizes standardized server structures (e.g., <Project_Path>/python/module_tts) and supports both raw text and HTML parsing. This setup serves as a blueprint for integrating AI-driven localization into high-traffic, scalable architectures.
Who should use this module?
Developers integrating automated VI-to-EN translation into high-traffic content pipelines.
Architects seeking a production-ready localization microservice for scalable web platforms.
Engineering teams optimizing multilingual content delivery with stable AI models.
How My Vietnamese-to-English Module Runs on a Flask AI Server
Short description for the article card
This article explains how my Vietnamese-to-English module runs on a Flask AI server, from route dispatch and model loading to text and HTML translation output. It also outlines the current translation direction, runtime flow, and practical limits.
Article body
My Vietnamese-to-English module runs inside the current Flask server, not as a separate public app. In the repo, the server adds the translate directory to sys.path, and the /translate route dispatches requests through translate_fb(...), which maps to main(...) in translate/server_4.py. The route reads content and category from form or query input and does not parse JSON body data.
The wrapper is fixed to Vietnamese-to-English by default. In server_4.py, the main entry uses src_lang="vi" and tgt_lang="en", and the /translate route does not override them. Because of that, requests sent to /translate follow one default direction unless the code is changed.
Translation uses facebook/nllb-200-distilled-600M. The tokenizer is loaded globally once, while the model pipeline is lazy-loaded through _get_pipeline() with a lock to avoid race conditions during first initialization. This lets later requests reuse the same pipeline in memory.
Language direction is enforced through the NLLB language map and generation settings. Vietnamese maps to vie_Latn, English to eng_Latn, the tokenizer source language is set before generation, and output is forced by forced_bos_token_id. This keeps the module returning English output when the target remains en.
For normal text, the module preserves leading and trailing spacing, translates only the stripped core content, and returns the original input unchanged if the text is empty after stripping. For HTML, it parses the document with BeautifulSoup, skips nodes such as script, style, and source, translates valid text nodes in batch, then writes them back while preserving node spacing. If category is not html, the dispatcher falls back to the text path.
The translation path also has limits. Input is truncated at max_length=512, output is capped by max_new_tokens=50, and long content can be cut on both sides. Cache and temp paths are moved to drive F: by default, or to HUSTMEDIA_AI_CACHE if that environment variable is set. The model normally stays in memory for faster reuse, but if TRANSLATE_RESET_EACH_CALL=1 is enabled, the pipeline resets and cleans memory after each request.
Technical configuration snapshot
CONFIG
Server route: /translate
Main wrapper: main(content, src_lang="vi", tgt_lang="en", category="text")
Target language map: en -> eng_Latn
Text mode: translate stripped core, preserve outer spacing
Input limit: max_length=512
Output limit: max_new_tokens=50
Optional reset mode: TRANSLATE_RESET_EACH_CALL=1
Route input: content, category from form/query
Translation model: facebook/nllb-200-distilled-600M
Source language map: vi -> vie_Latn
Direction control: forced_bos_token_id
HTML mode: BeautifulSoup parse + batch text-node translation
Cache path: F: or HUSTMEDIA_AI_CACHE
Current limitation: fixed VI -> EN, no JSON POST parsing, invalid target may return 500
Practical Use
Module Usage Guide
After the technical overview above, this guide explains how to use the Vietnamese-to-English module with short notes, drafts, product text, or support content.
1.Paste Vietnamese text or a simple HTML/text snippet into the input field.
2.Click Translate to English to generate the English version.
3.Review the output for meaning, names, product terms, and sentence clarity.
4.Use shorter sections when preparing content for review, documentation, or publishing.
Use the section below to experience the module directly. Start with a short Vietnamese draft, then adjust the input based on your content workflow.
Use the steps below to quickly test this module with your real content.
Vietnamese to English Translation
Current characters: 0/1000
Sample Inputs
Input: Vietnamese draft note. Output: English version for review.
Input: Vietnamese product or support text. Output: English for publishing.
Closing Notes
Reader Value
Readers can use this module pattern to turn Vietnamese notes, drafts, and support content into a more structured English workflow for review and publishing. In real projects, that helps reduce manual rewriting, keep translation handling more consistent, and support stable operation across content-focused workflows.
Conclusion
This Vietnamese-to-English module combines controlled translation routing, fixed language direction, and practical text handling into one maintainable service layer. It remains aligned with the platform's broader system integration and stable operation model.
By Hust Media • Written date: 10/18/2025 11:36:36
Was this content helpful to you?