Core Processing: Validation and Quality Workflow
Back to NotesThis note shows how input evaluation, automated validation, and quality-control checks improve record consistency, supporting platform growth through cleaner processing and stable workflows.
Written date: 05/01/2025 19:12:45Engineering Notes
Introduction
This workflow belongs to the validation layer of a web platform. It sits before deeper processing and controls how records are checked, filtered, and moved forward. You usually meet it when a website receives many records or user inputs that need consistent validation before later service flows.
- Technical context: This workflow covers input evaluation, automated validation, and quality control before deeper processing.
- Technical benefit: It improves record consistency, reduces unstable input states, and supports cleaner downstream flow.
Practical Notes
At the beginning of 2025, after entering a new relationship, I became more focused on keeping the system stable because I had less time to manually review large amounts of user input. That led me to build a more structured validation workflow so records could be checked earlier, filtered more consistently, and moved forward more safely. The diagram below shows the workflow more clearly.
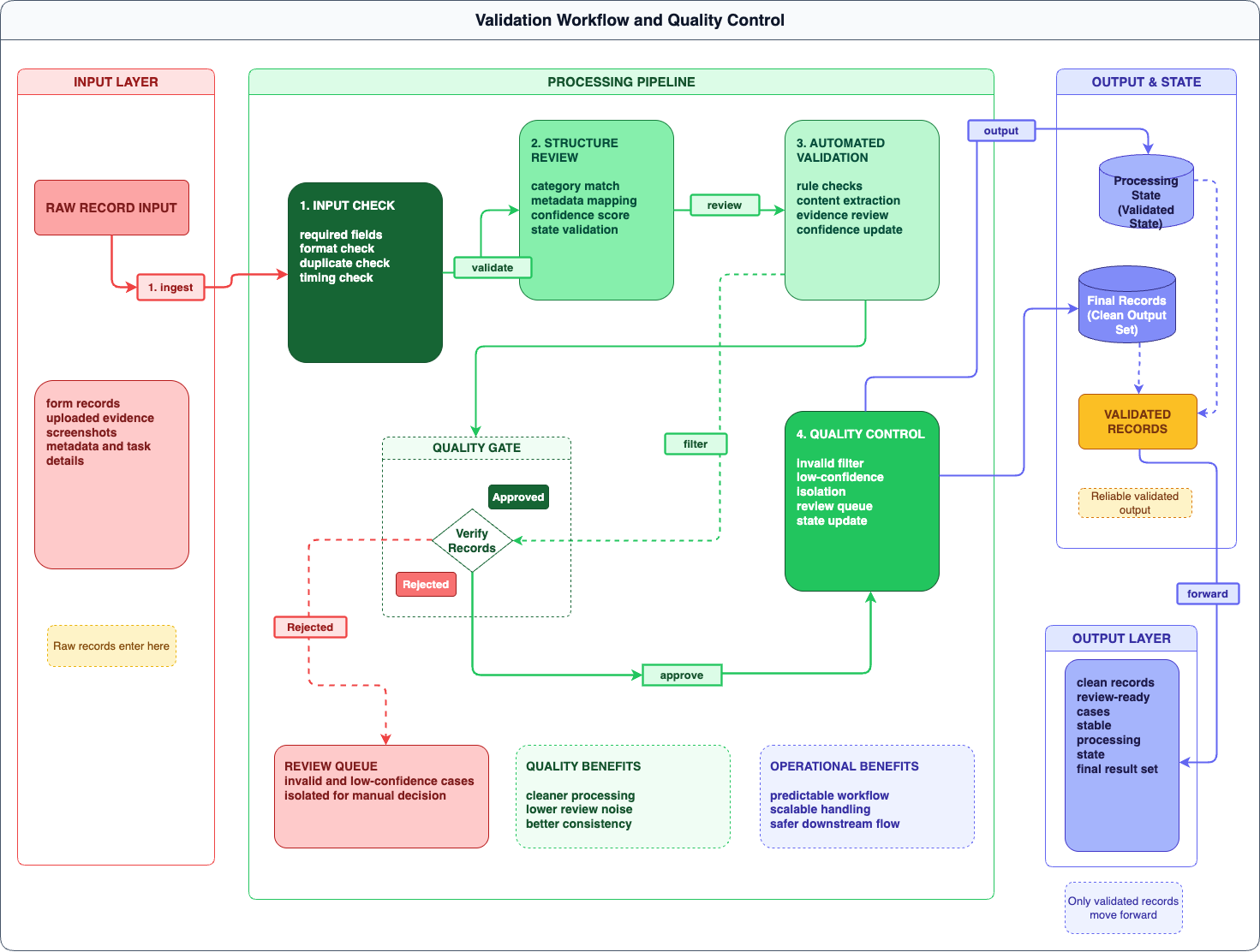
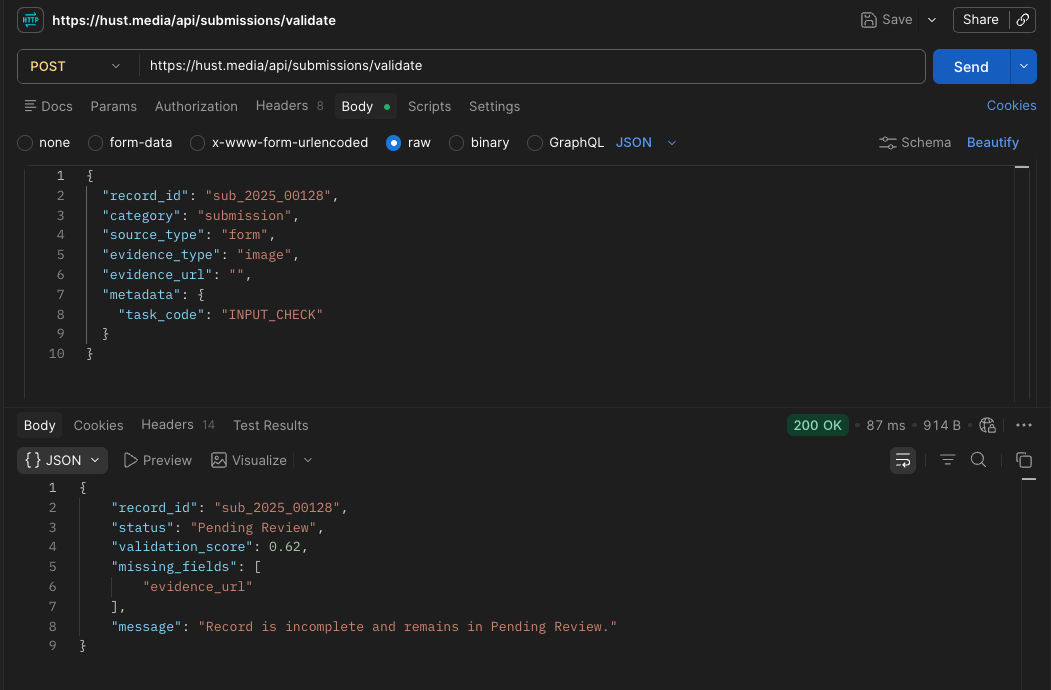
How validation and quality control guide records through review.
Input Evaluation Model
After this brief technical overview, the first layer to examine is the input stage.
Incoming data is treated as structured input inside a controlled workflow rather than as isolated submissions. The evaluation model checks input category, completeness, validation confidence, timing behavior, and submission state across JSON requests and evidence records from Web flows. In practice, fields such as user ID, task ID, service type, evidence type, metadata, and timestamps must remain consistent before the record moves forward, helping maintain stable processing quality across different flows and service conditions.
A simplified evaluation model can be represented as:
FORMULA
input_score = base_value
* input_weight
* validation_score
* consistency_factor
* timing_factorInputs:
input_weight: determined by input category, evidence type, expected structure, and processing priority.
validation_score: confidence generated after rule checks, evidence checks, and field verification.
consistency_factor: reflects how closely the submission matches expected format, metadata, task mapping, and normal processing behavior.
timing_factor: reduces the effect of incomplete, delayed, duplicated, or irregular submission flow.
In practice, the evaluation layer also checks required fields, duplicate windows, API input validity, and submission state before the record is promoted to the next step.
PHP
if ($missing_required || $duplicate_in_window || $invalid_state) {
$status = 'Rejected';
}This model helps assess input quality consistently while keeping downstream processing predictable.
Automated Validation Layer
Submitted evidence is processed by an automated validation layer that combines rule-based checks with content extraction methods. Its purpose is to confirm whether the input matches the expected format, context, and structural requirements before moving to the next stage. This layer sits between raw submission intake and task approval, helping normalize evidence such as screenshots, uploaded media, or structured request payloads before they affect scoring, reward flow, or final status.
By Hust Media • Written date: 05/01/2025 19:12:45
Related Insights
Hust Media System Overview
10/1/2025
Engineering Notes
Core Engine: Hybrid Frontend Architecture
8/31/2025
Engineering Notes
Core Engine: Credit Scoring and Abuse Prevention
7/31/2025
Engineering Notes
Hust Media Public API v3
6/30/2025
Engineering Notes
Threat Signal Verification and Risk Indexing
5/31/2025
Engineering Notes
Core Processing: Validation and Quality Workflow
5/1/2025
Engineering Notes
Was this content helpful to you?